By following this guide, you will be able to successfully self-host your preferred DeepSeek model on a home lab or home office server, harnessing the potential of these AI models in a private and controlled environment. DeepSeek is a powerful AI model that can be self-hosted locally for faster performance, improved privacy, and flexible configuration. This… continue reading.
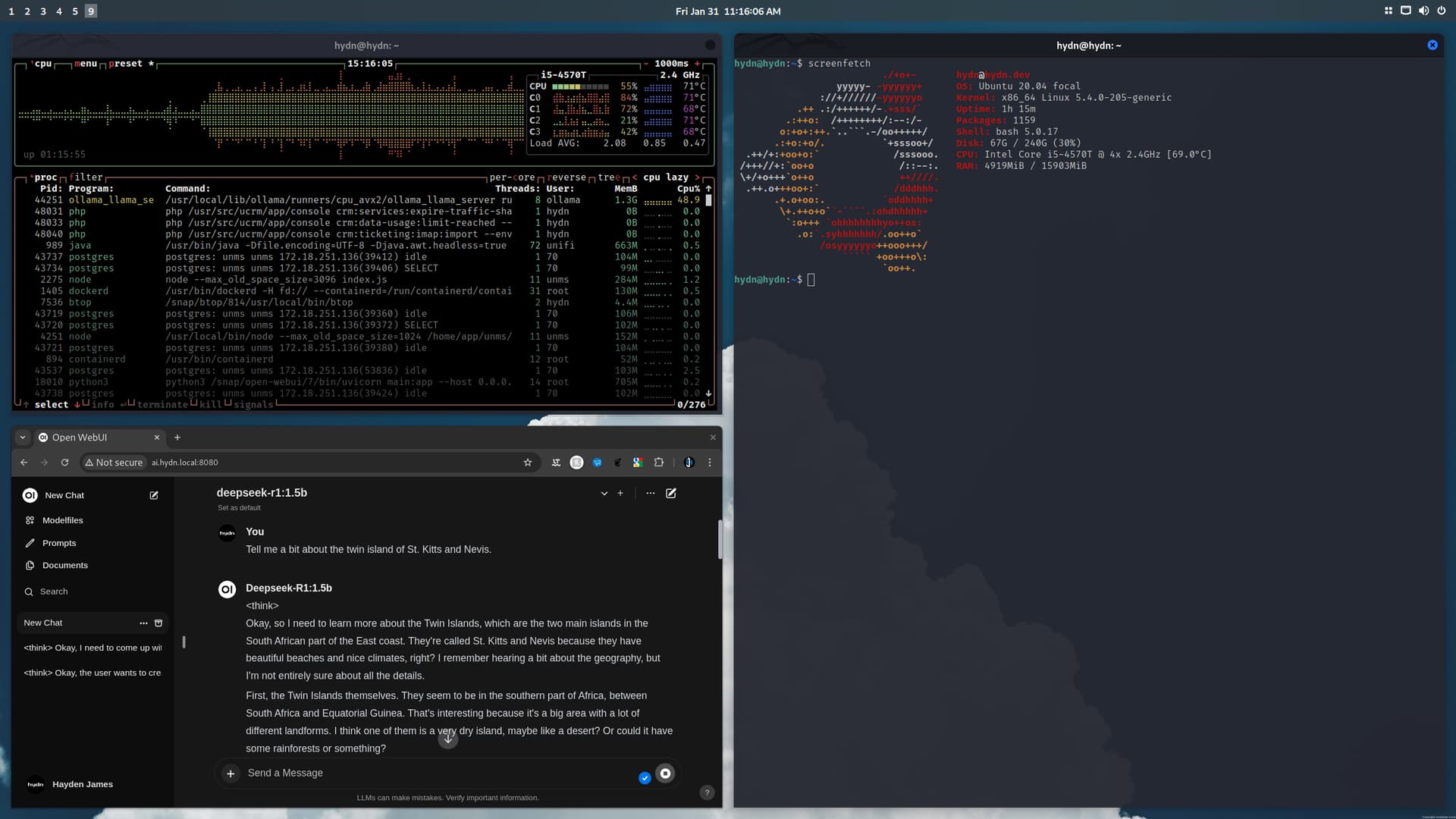
So I was able to get this to work locally within my home network. Setting up to hydn.local. I’m only running the 1.5b model because above that is slow. The server is an OLD ThinkCentre tiny with basic CPU and 16 GB ram. It runs well and now my wife and me, and guests, can use it in the browser.
Here is a rough guide for hardware recommendations for 8-bit quantized DeepSeek R1. Keep in mind these are rough numbers and will vary depending on your setup. Larger models (especially 70B and 671B) are usually run in multi-GPU or distributed setups so these numbers are for a “per-node” or “per-GPU” baseline in those cases.
Hardware requirements for 8-bit quantized DeepSeek R1
Model
System RAM
CPU Cores
GPU VRAM
Recommended Nvidia GPU
Recommended AMD GPU
1.5B
16 GB
4
8 GB
RTX 4060 Ti 8GB
RX 7600 8GB
7B
32 GB
8
16 GB
RTX 4060 Ti 16GB
RX 7700 XT 12GB
8B
32 GB
16
16 GB
RTX 4060 Ti 16GB
RX 7800 XT 16GB
14B
64 GB
24
16–24 GB
RTX 4090 24GB
RX 7900 XT 24GB
32B
128 GB
32
32–48 GB
RTX A6000 48GB
Instinct MI250X
70B
256 GB
48
48+ GB
A100 80GB
Instinct MI250X
671B
1 TB+
64+
80+ GB
H100 80GB (multi‑GPU)
Instinct MI300 (multi‑GPU)
Notes:
– A 16GB GPU can work with aggressive optimization but a bit more VRAM (or multi-GPU) gives more headroom.
– For production use (especially with the larger models), you may need to further tune the configuration or use multi‑GPU strategies to handle peak memory and throughput requirements.
Here is a rough guide for hardware recommendations when running 4-bit quantized versions of these models. 4-bit quantization halves the raw weight memory compared to 8-bit so you can often use GPUs with lower VRAM and sometimes even scale down the system RAM and CPU core count. But overheads (activations, caching, OS, framework requirements) mean these are just starting points not hard rules. Larger models (especially 70B and 671B) will likely still need distributed or multi-GPU.
Hardware requirements for 4-bit quantized DeepSeek R1
Model
System RAM
CPU Cores
GPU VRAM
Recommended Nvidia GPU
Recommended AMD GPU
1.5B
16 GB
4
8 GB
RTX 3050 (8 GB)
RX 6600 (8 GB)
7B
16 GB
6
8 GB
RTX 3060 (8 GB)
RX 6600 XT (8 GB)
8B
16–32 GB
8
8–12 GB
RTX 3060 (12 GB)
RX 6700 XT (12 GB)
14B
32 GB
12
12–16 GB
RTX 4060 Ti (16 GB)
RX 7800 XT (16 GB)
32B
64 GB
16
16–24 GB
RTX 4090 (24 GB)
RX 7900 XTX (24 GB)
70B
128 GB
16–24
24–32 GB
A100 40 GB (or H100)
Instinct MI250X
671B
512 GB+
32+
40+ GB
A100/H100 (multi‑GPU)
Instinct MI300 (multi‑GPU)
Notes:
– For the smaller models (1.5B, 7B, 8B) 4-bit quantization can run on mid-range GPUs with 8-12 GB VRAM.
– For 14B a mid-range GPU like the RTX 4060 Ti (or RTX 4070) can be enough in 4-bit mode.
– Even with 4-bit quantization larger models (32B and above) are still heavy hitters. For example a 32B model might fit in a 24-GB GPU (like the RTX 4090) with optimizations and offloading, while 70B and 671B will generally require enterprise-grade, data-center GPUs and often multi-GPU/distributed configurations.
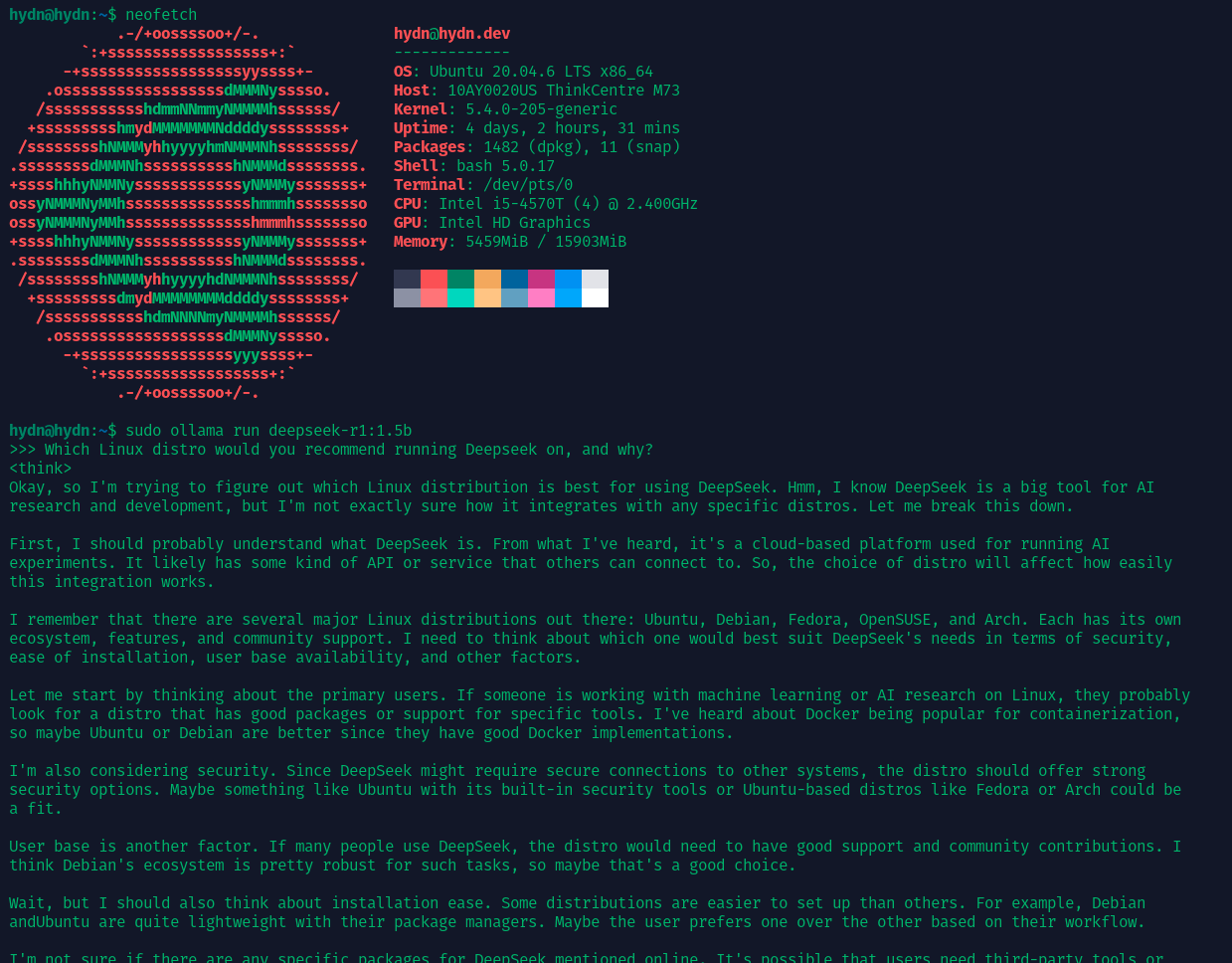
For context, here’s 4-bit 1.5b running on ThinkCentre Tiny (no GPU):